char의 크기가 1바이트라면, 한글은 어떻게 표현될까?
char의 크기는 1바이트, 아스키 코드 기준 127개를 표현한다.
근데 생각해보면 한글을 조합하면 127은 거뜬히 넘어갈텐데, 어떻게 표현될까?
멀티바이트 방식의 문자 표현
char test[15]="abc한글123";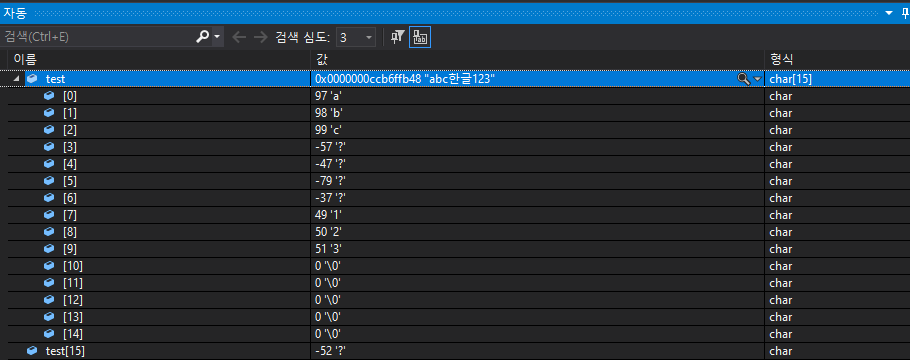
'a' 'b' 'c' 와 '1' '2' '3' 은 1바이트, '한' '글' 은 2바이트가 할당되었다.
이처럼 상황에 따라서 할당되는 공간이 다르다면 멀티바이트 방식이라고 한다.
이는 현재 잘 쓰지 않고 있다.
호환성의 문제 떄문에 마이크로소프트의 윈도우에서 잔재되어있는 시스템.
표준으로 쓰이지 않는 방식이다.
와이드바이트 시스템, UNICODE
모든 문자를 2바이트로 표현하는 방식이다.
유니코드 문자셋을 사용하는 것이 많은 기기와의 호환성, 그리고 다양한 문자를 표현하는 부분에 있어서 훨씬 유리하다.
⇒그래서 이제부터는 char대신에 wchar_t 를 이용하여 작성하는 것이 좋다!
두 표현 방식의 차이점
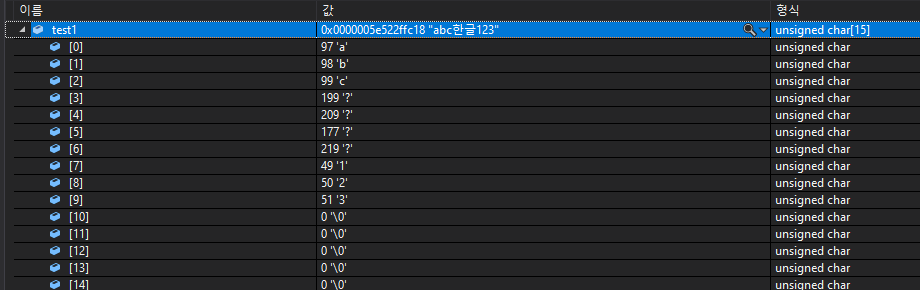
char test1[15] = "abc한글123";
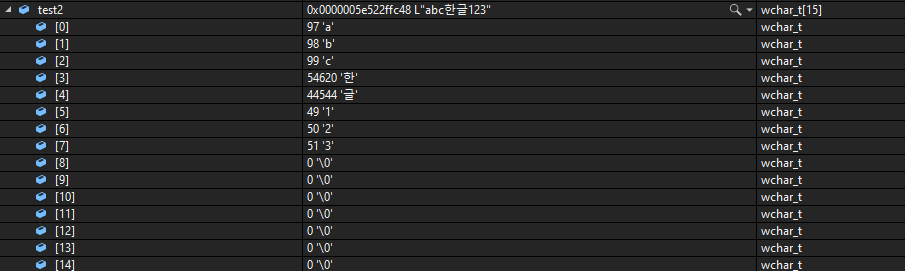
wchar_t test2[15] = L"abc한글123";
cout << strlen(test1) << endl;
cout << wcslen(test2) << endl;출력:
10
8
두 표현 방식은 이런 상황에서 문제가 발생한다.
strlen과 wcslen은 각각 문자의 개수를 출력해주는 함수이다.
문자열 "abc한글123" 은 8자가 맞는데도, 멀티바이트 방식의 문자 표현 방식에서는
'한' , '글' 이 2바이트씩 할당받기 때문에 10자라고 인식하는것이다.
하지만, 유니코드 방식의 문자 표현 방식에서는 모든 공간의 크기가 일정하고,
그 안에서 모두 표현이 되므로 문제가 없이 출력된다.
여기서의 상황을 보자.
'한' 이라는 문자에서는 test1의 멀티바이트 형식에서는 [3],[4]번 인덱스가 나누어져 199 / 209 각각
1바이트씩, test2의 와이드바이트 형식에서는 54620 으로, 2바이트의 크기가 할당되었다.
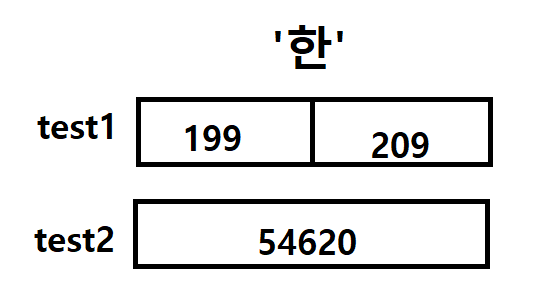
그림으로 본다면 이런 방식으로 각각의 표현방식에 차이가 있는 것이다.
매우 불편하지 않은가?
'프로그래밍 언어 > C++ [기본]' 카테고리의 다른 글
| [C++기본] 23.문자열-4 (0) | 2021.09.23 |
|---|---|
| [C++기본] 22.문자열-3 (0) | 2021.09.23 |
| [C++기본] 20.문자열-1 (0) | 2021.09.23 |
| [C++기본] 19.문자 (0) | 2021.09.17 |
| [C++기본] 18.void 포인터 (0) | 2021.09.02 |